

In dem vierten Teil der Blogserie „IT Security in Web Anwendungen“ thematisieren wir das HTTP(S) Übertragungsprotokoll, den Zustand von HTTP(S)-Anfragen sowie Erweiterungen zu dem Ursprungsentwurf und einen Blick aus Sicht der IT-Sicherheit. Anhand konkreter theoretischer Beispiele wollen wir die wichtigsten Punkte im Bezug auf IT-Security im HTTP(S)-Umfeld aufzeigen und Best Practices auflisten.
In unserem ersten Post dieser Blogserie sind wir das Thema „Injections“ angegangen und haben gezeigt, wie diese zustandekommen bzw. zu verhindern sind. In dem zweiten Teil der Serie sind wir auf File Up-/Download und Storage eingegangen und haben allgemeine Sicherheitsrisiken sowie Prävention und Alternativen aufgelistet. In dem dritten Teil thematisieren wir Sessions und Session Hijacking-Attacken sowie einen möglichen Schutz gegen solcher Attacken.
In dem kommenden Posts der Blogserie möchten wir uns tiefergehend mit den verschiedenen Bereichen der IT Security beschäftigen. In insgesamt neun Blogposts möchten wir tiefergehend auf verschiedene Szenarien eingehen, mögliche Schutzmechanismen präsentieren und diese – wenn möglich – durch praktische Beispiele demonstrieren. Nach Blogpost #9 werden wir diese Serie und weitere Tipps und Tricks als PDF zur Verfügung stellen. Sie können sich unter dem nachfolgenden Formular zum Newsletter anmelden, um das PDF zu erhalten:
Das HTTP(S)-Protokoll und der Zustand
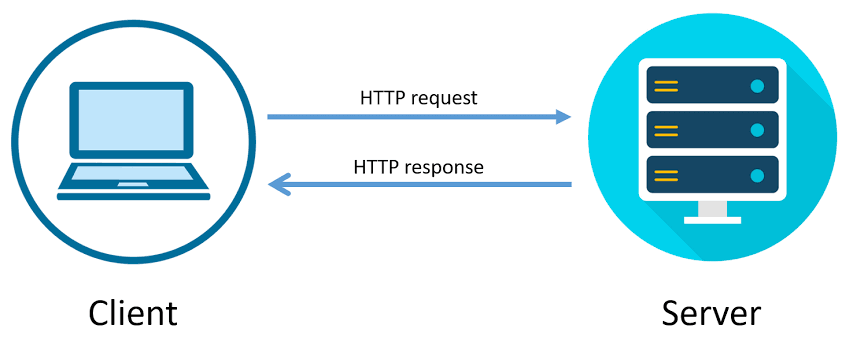
Um es auf den Punkt zu bringen: Das HTTP(S)-Protokoll ist zustandslos. Das bedeutet, dass eine Anfrage eines Clients in dem Moment „vergessen“ wird, in dem der Server mit „Erfolg“ oder „Fehler“ (mehr dazu weiter unten) antwortet. Jeder Request (egal ob subsequente Anfragen des gleichen Clients oder nicht) wird von dem Server also so behandelt, als wäre die Anfrage „neu“.
Durch Cookies kann dem HTTP(S)-Protokoll jedoch ein gewisser Zustand verliehen werden. Cookies sind kleine Textinformationen die mit dem HTTP(S)-Header zwischen Client und Server ausgetauscht werden. Dabei besteht ein Cookie aus den folgenden Informationen:
- Name: der Name des Cookies, der eine Information trägt
- Wert: die Information, die zwischen Client und Server ausgetauscht wird
- Domain: die Domain, auf die das Cookie gesetzt wird
- Pfad: der Pfad auf einer Domain
- Expires: die Gültigkeitsdauer des Cookies
- Max-Age: die Höchstdauer des Cookies
- HttpOnly: Cookies für JavaScript unerreichbar machen
- Secure: HTTP oder HTTPS
Set-Cookie und Cookie Header
In dem HTTP(S)-Header können zwei Felder genutzt werden, um Cookies zu setzen: Set-Cookie und Cookie. Dabei wird der Set-Cookie-Header von dem Server genutzt um Cookies dem Client zu übertragen:
$ curl -i https://www.google.com
HTTP/2 200
date: Sun, 17 Jul 2022 10:32:13 GMT
content-type: text/html; charset=ISO-8859-1
set-cookie: theme=light; expires=Fri, 13-Jan-2023 10:32:13 GMT; path=/; domain=.google.com; Secure; HttpOnly; SameSite=laxDer Client wiederum nutzt den Cookie-Header, um die gesetzten Cookies an den Server zu übertragen:
$ curl -iv https://www.google.com
GET google.com HTTP/2
Host: https://www.google.com
Cookie: theme=lightCookies werden genutzt um Sessions zwischen Client und Server zu starten. Sessions sind (meist) kurze Sitzungen zwischen Client und Server, um bspw. einen Warenkorb in einem Online-Shop über Anfragen hinweg erhalten zu haben.
Warum Cookies keine Lösung sind
Dank dem erweiterbaren Design des HTTP(S)-Protokolls könnte man auf die Idee kommen, Cookies maximal auszunutzen um den Zustand einer Anwendung erhalten zu lassen. Zusammen mit HTTP 1.1, welches mehrere Anfragen pro aktiver Verbindung zu einem Server, könnte so – theoretisch – eine performante und zustandsbehaftete Anwendung erstellt werden.
Leider sieht dies in der Praxis nicht ganz so aus. Zunächst einmal gibt es keine Garantie darüber, ob ein Cookie auf Clientseite gespeichert wurde. Des Weiteren ist die Verweildauer eines Cookies im Bestfall wie in dem Set-Cookie-Header spezifiert – eine Anwendung, der Browser oder aber auch der Benutzer kann jederzeit das Cookie löschen, modifizieren oder sonst etwas damit machen. Und letztlich sind Cookies kleine Texte (meist 4KB) und in ihrer Anzahl begrenzt. Sowohl für eine spezifische Domain als auch in der Anzahl aller Cookies, die ein Browser speichert, besteht eine Obergrenze. Wird diese erreicht, wird das älteste Cookie gelöscht und das neue gesetzt.
Cookies bringen eine gewisse „Altlast“ mit sich
Wie bereits erwähnt gibt es keine Möglichkeit zu prüfen ob ein Cookie gesetzt ist oder noch vorhanden ist. Der einzige Weg ist der Reload der Webpage und das Prüfen, ob das Cookie vorhanden bzw. mit dem erwarteten Wert gesetzt ist. Des Weiteren wird manche Logik zwischen Client und Server von dem Client (z.B. Browser) oder Webserver implementiert – sind Voraussetzungen nicht erfüllt, wird das Cookie nicht an den Server übertragen, obwohl es gesetzt ist. Ein Entwickler oder Admin verbringt dann nicht selten viel Zeit mit der Frage nach dem Warum.
Zustandslosigkeit ist der Schlüssel zur Skalierung
Ein weiterer Grund, weswegen die Zustandslosigkeit des HTTP(S)-Protokolls so strikt wie möglich befolgt werden sollte, ist das Skalierungs-Potenzial. Bei zustandsbehafteten Anfragen über mehrere Server hinweg, orchestriert durch einen Load-Balancer, stehen oft vor dem Problem: wie mache ich den Zustand über alle Server hinweg bekannt? Dies gilt ebenso für die Applikationslogik, die die Anfragen entgegennehmen und verarbeiten sollen.
HTTP(S) und Zustand: Best Practices und Lösungsansätze
Das wichtigste zuerst: Es gibt keine Standardlösung! Während in gewissen Szenarien, vor allem kleinen Anwendungen der Session/Cookie-Weg ein durchaus erprobter Weg ist, kann dies für eine Banking-Anwendung schon ganz anders aussehen. Es spielen viele wichtige Faktoren zusammen, so z.B. ob Sie Drittanbieter-Lösungen (OAuth von Drittparteien) vertrauen, wie viel Information Sie preisgeben möchten (z.B. einen Authentifizierungs-Token als Teil des Headers) oder ganz einfache Sachen wie z.B. die Umgebung, in der die Anwendung laufen soll (Intranet, Internet, etc).
Dennoch möchten wir Ihnen einige Best Practices und Lösungsansätze mitgeben, die sich für uns gewährt haben:
- Gestalten Sie Ihre Anwendungen und API’s so zustandslos wie möglich: meiden Sie Cookies und Sessions, wo möglich. Setzen Sie auf OAuth, JWT Token oder eigene Authentifizierungstoken. Schicken Sie diese mit jeder Anfrage an den Server und lassen Sie den Server die Berechtigungen zu der gewünschten Aktion prüfen.
- Nutzen Sie ausschließlich verschlüsselte Kommunikation: setzen Sie auf jeden Fall auf SSL/TLS. Verweigern Sie unsichere Anfragen und geben Sie niemals Informationen im Klartext heraus. Generieren Sie Token selbst, achten Sie darauf, dass niemand aus Ihnen den Token auf die Identität des Benutzers zurückführen kann. Sie können einzelne Token widerrufen, falls Sie der Meinung sind dass diese entwendet wurden.
- Machen Sie sich mit HTTP(S) Verben und REST vertraut: nutzen Sie bspw. GET nicht um sensible Daten zu übertragen – GET-Parameter werden der URL hinzugefügt und landen in diversen Logs oder Anwendungen. Nutzen Sie
POSTum eine Resource zu erstellen,PUTum diese zu verändern undPATCHum sie teilweise zu updaten. Verweigern Sie alle Anfragen die dieser Logik nicht folgen. - Nutzen Sie HTTP(S) Status Codes: Es ist immer wieder verwunderlich wie viele Anwendungen mit einem HTTP OK (200) antworten und die eigentliche Response über die gewünschte Operation in den Body „verstecken“. Vermeiden Sie diesen Ansatz, da dies auch einen gewissen (und schlechten) „Zustand“ simuliert und gewisse Kenntnisse Ihrer API’s voraussetzt. Viele Anwendungen und Browser haben Bordmittel zur Fehlerbehandlung (z.B. für 404 oder 500). Wenn diese jedoch nie auftreten, müssen Sie sich selbst darum kümmern.
- Haben Sie ein Auge auf verdächtigen Anfragen: Sie sollten sehr früh in der Validierung der Anfrage darauf achten, dass Sie verdächtige Anfragen ausfiltern. Dies kann neben Anfragen ohne Header oder Body, sicherheitskritischen Parametern (z.B. XSS) auch einfach eine erhäufte Anzahl von Anfragen pro Sekunde sein. Je nach Art und Qualität der Anfrage können diese Art von Attacken (DDoS) Ihre Server schnell in die Knie zwingen. Führen Sie RateLimiter ein und sperren Sie verdächtige IP-Adressen (für eine gewisse Zeit) aus. Haben Sie eine zustandslose Architektur, müssen Sie nicht den Inhalt der Anfrage auswerten.
Fazit
Wie aus dem Blogpost heraus geht, haben wir sehr gute Erfahrung mit zustandslos API’s gemacht und sehen die Vorteile gegenüber zustandsbehafteten Anwendungen überwiegen. Mit unserer Software-as-a-Service (kurz: SaaS) Lösung Keestash bspw. haben wir nicht nur für sichere API’s gesorgt, sondern konnten durch mit nahezu keiner Anpassung auf API-Seite mobile Clients (für iOS und Android) erstellen. Dank der zustandslosen Natur der API sind die Clients (Web-Frontend, mobile Anwendungen) nahezu komplett unabhängig von einander bzw. der API.
Benötigen Sie Beratung, Umsetzung oder Audits in dem Bereich IT-Security? Sprechen Sie uns noch heute an, wir freuen uns auf Sie!